Residual Networks (ResNets)
- Why is this arch called Residual networks? What is residual? ChatGPT: In the context of ResNets, the residual refers to the difference that the network needs to learn to add to the input x to reach the final desired output.
- Andrew Ng said called 100-layer network deep. But he said that 6 years ago. OK, so GPT3, trained 3 years ago, only has 96 layers. but the number of parameters, 175 billions, is probably a lot more than that of the 100–layer network 6 years ago.
- motivation of resnets: In theory, the deeper a neuron net, the better the training performance. however, in reality, at a certain point, the depth of a neuron net actually worsens the training performance because training simply gets harder and less effective. Residual network is designed to combat this problem.
- Where does increasing difficulties in training come from? AN: problems like vanishing gradient, exploding gradient, parameter scale and initialization and so on
- How does the design combat the training difficulties? AN: the design provides a direct path of gradients where gradients can skip the main path, which might shrink or multiply the gradients in an undesirable way and flow directly from output to input during backprop, therefore, maintain strength and stability of gradients during training
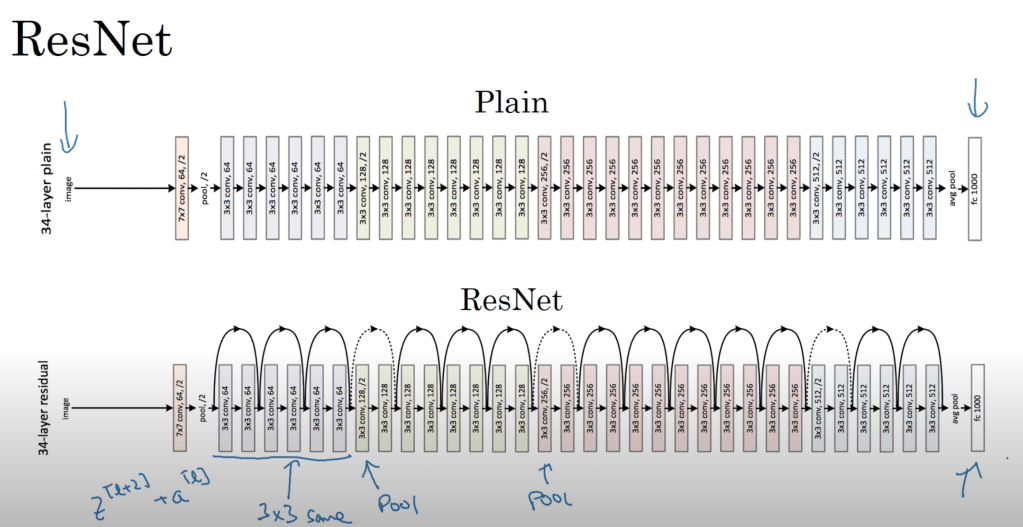
- Structure of a residual block: it consists of a main path and a shortcut/skip connection. The main path and the shortcut run in parallel. They are added before the last non-linearity of the block.!

- ChatGPT: “L2 regularization, also known as ridge regression or Tikhonov regularization, is a technique used in machine learning to prevent overfitting. L2 regularization addresses this by adding a penalty to the loss function used during the training of a model.”
- ChatGPT: “By penalizing large weights, the model becomes simpler (since weights have lower values), which can help in reducing the model’s variance and thus, improving its generalization capabilities on new data”
- ChatGPT: “The term “simpler” in the context of machine learning models, especially when referring to the impact of regularization, relates primarily to the complexity of the model’s decision surface or function.”
- ChatGPT: “Large weights can cause the model to react very sensitively to small changes in the input features, leading to a more erratic and complex decision boundary. This behavior can be especially problematic as it might cause the model to capture noise and fine-grained fluctuations in the training data (overfitting).”
- The identity function
- It in mathematics is defined as
f(x) = x - Why did Andrew Ng said “Identify function is easy for residual block to learn”? AN: because the learning target for the main path becomes the residual part of the transformation. Instead of a full transformation from input to output, a residual block simply needs to learn the difference between input and output. When the optimal function for the block is close to the identity, the layer simply needs to learn near-zero functions, which is easier than learning a complete transformation.
- the flip side is it’s difficult for a deep plain nn even to learn the identity function
- What is Ng’s explanation on the effectiveness of resnets? AN: he thinks the effectiveness comes from the fact that identity function is easy to learn, implying an extra residual block at least won’t hurt baseline performance (i.e., the nn the extra residual block is appended to). And often the layers in the block learns something useful, so it improves the performance compared to the baseline
- It in mathematics is defined as
- The overall arch

Leave a comment